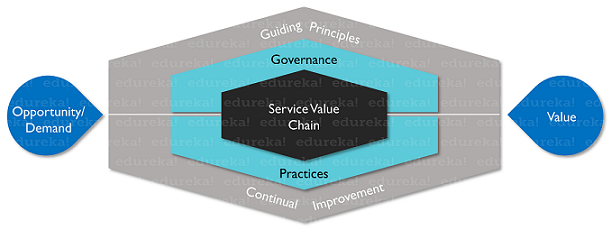
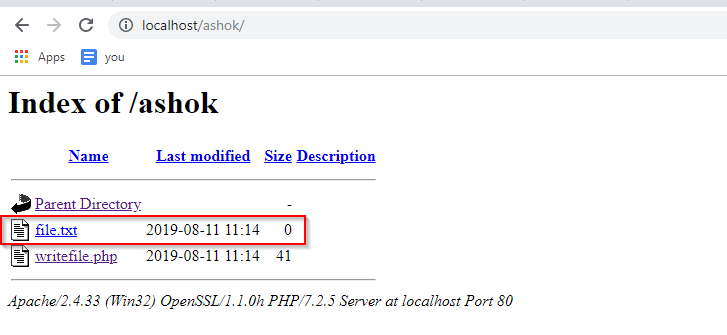
Обязанности администратора Hadoop
В этом блоге об обязанностях администратора Hadoop обсуждается объем администрирования Hadoop. Работа администратора Hadoop пользуется большим спросом, поэтому изучите Hadoop прямо сейчас!

В этом блоге об обязанностях администратора Hadoop обсуждается объем администрирования Hadoop. Работа администратора Hadoop пользуется большим спросом, поэтому изучите Hadoop прямо сейчас!
Apache Spark стал великим достижением в области обработки больших данных.
Apache Hadoop 2.x состоит из значительных улучшений по сравнению с Hadoop 1.x. В этом блоге рассказывается о Федерации кластерной архитектуры Hadoop 2.0 и ее компонентах.
Это дает представление об использовании системы отслеживания вакансий.
Apache Pig имеет несколько предопределенных функций. Сообщение содержит четкие шаги по созданию UDF в Apache Pig. Здесь коды написаны на Java и требует наличия библиотеки Pig.
Архитектура HBase Storage состоит из множества компонентов. Давайте посмотрим на функции этих компонентов и узнаем, как записываются данные.
Apache Hive - это пакет хранилища данных, созданный на основе Hadoop и используемый для анализа данных. Hive ориентирован на пользователей, знакомых с SQL.
Внедрение Apache Spark с Hadoop в больших масштабах ведущими компаниями свидетельствует об их успехе и его потенциале, когда речь идет об обработке в реальном времени.
NameNode High Availability - одна из наиболее важных функций Hadoop 2.0. NameNode High Availability с Quorum Journal Manager используется для обмена журналами редактирования между активным и резервным NameNode.
Обязанности разработчика Hadoop включают множество задач. Должностные обязанности зависят от вашего домена / сектора. Эта роль сродни роли разработчика программного обеспечения.
Модели данных Hive содержат следующие компоненты, такие как базы данных, таблицы, разделы и сегменты или кластеры. Hive поддерживает такие примитивные типы, как целые числа, числа с плавающей запятой, двойные числа и строки.
Эти 4 причины перейти на Hadoop 2.0 рассказывают о рынке труда Hadoop и о том, как он может помочь вам ускорить карьеру, открывая для вас огромные возможности трудоустройства.
В этом блоге мы будем запускать примеры Hive и Yarn на Spark. Сначала создайте Hive and Yarn на Spark, а затем вы можете запускать примеры Hive и Yarn на Spark.
Цель этого блога - научиться переносить данные из баз данных SQL в HDFS, как передавать данные из баз данных SQL в базы данных NoSQL.
Сертифицированный разработчик Cloudera для Apache Hadoop (CCDH) - это толчок в карьере. В этом посте обсуждаются преимущества, схемы экзаменов, учебное пособие и полезные ссылки.
В этом блоге представлен обзор архитектуры высокой доступности HDFS и того, как установить и настроить кластер высокой доступности HDFS за простые шаги.
Apache Kafka продолжает оставаться популярным, когда дело касается аналитики в реальном времени. Вот посмотрите на это с точки зрения карьеры, обсуждая возможности карьерного роста и требования к работе.
Apache Kafka обеспечивает высокую пропускную способность и масштабируемые системы обмена сообщениями, что делает его популярным в аналитике в реальном времени. Узнайте, как руководство Apache kafka может вам помочь
Это сообщение в блоге - глубокое погружение в Pig и его функции. Вы найдете демонстрацию того, как вы можете работать с Hadoop с помощью Pig без зависимости от Java.
В этом блоге обсуждаются предварительные условия для изучения Hadoop, основы Java для Hadoop и ответы на вопрос, нужна ли вам Java для изучения Hadoop, если вы знаете Pig, Hive, HDFS.