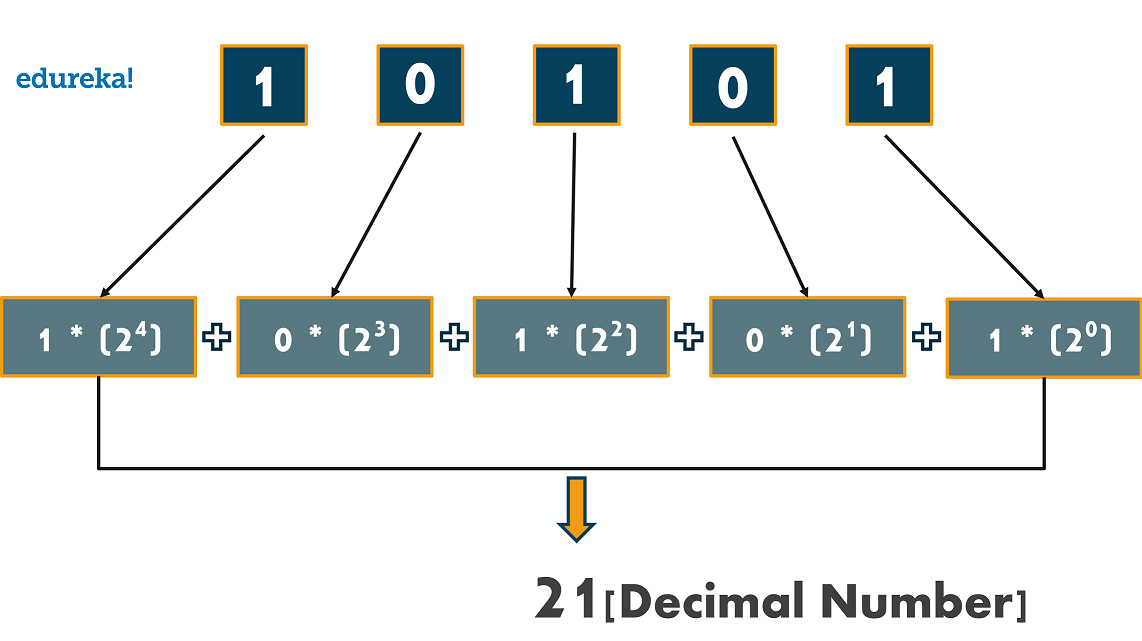
Spark vs Hadoop: какая платформа для больших данных лучшая?
В этом сообщении в блоге говорится о apache spark и hadoop. Это даст вам представление о том, какой фреймворк для больших данных лучше выбрать в различных сценариях.

В этом сообщении в блоге говорится о apache spark и hadoop. Это даст вам представление о том, какой фреймворк для больших данных лучше выбрать в различных сценариях.
Этот блог поможет вам понять, как установить и настроить плагин sbteclipse, с пошаговыми инструкциями по запуску приложения Scala в Eclipse IDE.
В этом сообщении блога объясняется, почему вы должны начать работу с Apache Spark после Hadoop и почему изучение Spark после освоения Hadoop может творить чудеса для вашей карьеры!
Это руководство по Apache Drill дает вам всю информацию, необходимую для начала работы с механизмом запросов Apache Drill, использованием с Hadoop, Big Data и Apache Spark.
В этом блоге Spark Hadoop рассказывается все, что вам нужно знать об Apache Spark combByKey. Найдите средний балл на одного студента с помощью метода combByKey.
Apache Falcon - это новая платформа управления данными для экосистемы Hadoop, которая упрощает обработку каналов и управление потоками в кластерах Hadoop. Узнайте, как его настроить.
В этом блоге Apache Spark подробно описаны аккумуляторы Spark. Изучите использование аккумулятора Spark на примерах. Аккумуляторы Spark похожи на счетчики Hadoop Mapreduce.
Узнайте все об Apache Flink и настройке кластера Flink в этом блоге. Flink поддерживает обработку в реальном времени и пакетную обработку и является обязательной технологией больших данных для аналитики больших данных.
В этом сообщении блога обсуждается распределенное кэширование с широковещательными переменными и начинается эффективное распределение больших значений в программировании на Spark.
Сертификаты CCA и CCP от Cloudera заменили экзамены CCDH и CCSHB. В этом блоге рассказывается все, что вам нужно знать о новых сертификатах.
В этом сообщении блога обсуждаются преобразования с отслеживанием состояния с использованием окон в Spark Streaming. Узнайте все об отслеживании данных по пакетам с помощью D-Stream с отслеживанием состояния.
В этом сообщении блога обсуждаются преобразования с отслеживанием состояния в Spark Streaming. Узнайте все о совокупном отслеживании и повышении квалификации для карьеры в Hadoop Spark.
Технологии Hadoop и Big Data революционизируют аналитику здравоохранения. В этом блоге о больших данных в сфере здравоохранения обсуждается, как аналитика больших данных может улучшить медицинское обслуживание.
Это сообщение в блоге о Hadoop Streaming представляет собой пошаговое руководство по написанию программы Hadoop MapReduce на Python для обработки огромных объемов больших данных.
В этом блоге, посвященном учебнику по большим данным, вы найдете полный обзор больших данных, их характеристик, приложений, а также проблем, связанных с большими данными.
Этот блог с учебным пособием по HDFS поможет вам разобраться в HDFS или распределенной файловой системе Hadoop и ее функциях. Вы также кратко изучите его основные компоненты.
В этом руководстве по Splunk вы поймете разницу между Splunk, ELK и Sumo Logic и определите, какой из этих инструментов подходит вам лучше всего.
В этом блоге с примерами использования Splunk вы узнаете, как Domino's Pizza использовала Splunk, чтобы получить представление о поведении потребителей и сформулировать свои бизнес-стратегии.
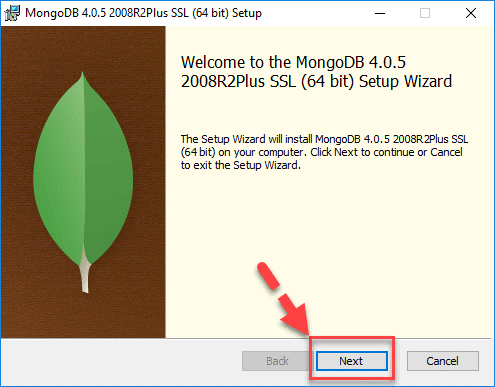
Это руководство представляет собой пошаговое руководство по установке кластера Hadoop и его настройке на одном узле. Все шаги по установке Hadoop относятся к машине CentOS.
В этом блоге рассказывается о различных командах HDFS, таких как fsck, copyFromLocal, expunge, cat и т. Д., Которые используются для управления файловой системой Hadoop.