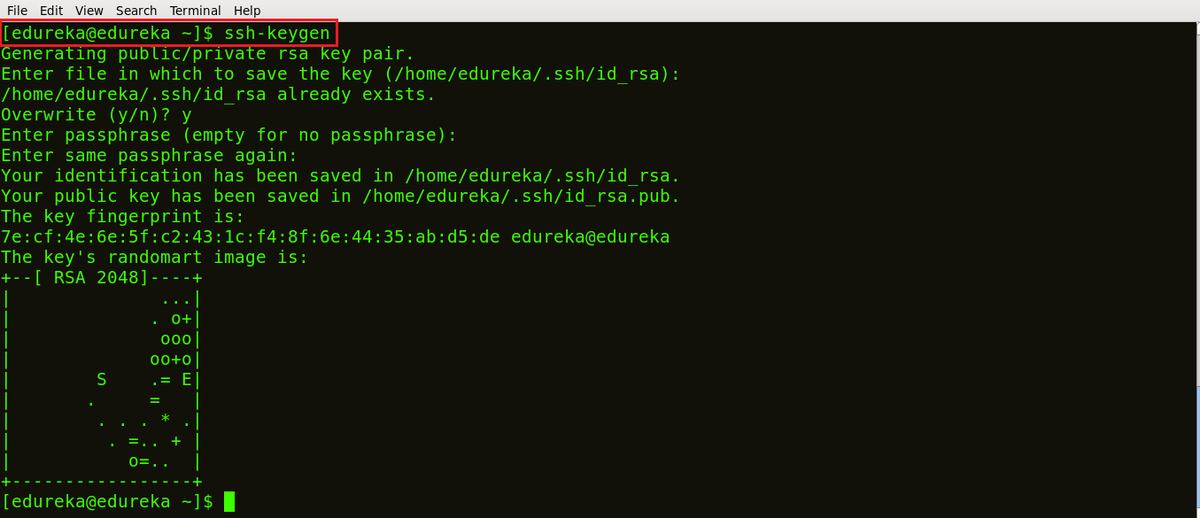
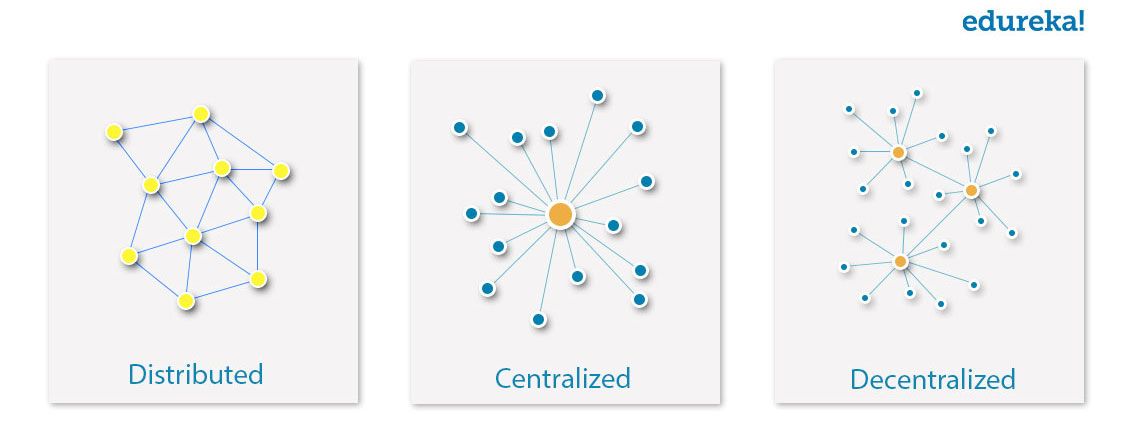
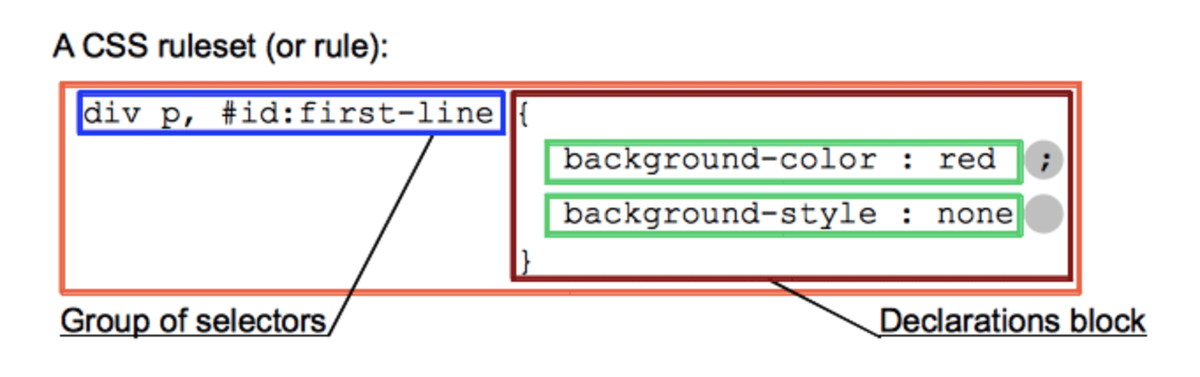
Как запускать сценарии Hive?
Это руководство по запуску сценариев Hive. Запуск этого скрипта сократит время и усилия, которые мы вкладываем в написание и выполнение каждой команды вручную.

Это руководство по запуску сценариев Hive. Запуск этого скрипта сократит время и усилия, которые мы вкладываем в написание и выполнение каждой команды вручную.
Прочтите это сообщение в блоге, чтобы создать свой первый скрипт Apache Pig. Сценарии Apache Pig используются для коллективного выполнения набора команд Apache Pig.
Программирование Pig: сценарий Apache Pig с UDF в режиме HDFS. Вот сообщение в блоге для запуска сценария Apache Pig с UDF в режиме HDFS ...
В этом посте обсуждается присоединение сторон карты Hadoop к Vs. присоединиться. Также узнайте, что такое уменьшение карты, таблица соединения, сторона соединения, преимущества использования операции соединения стороны карты в Hive.
Вы знаете, как добавлять или удалять узлы в кластере Hadoop? Вот запись в блоге - Ввод в эксплуатацию и вывод из эксплуатации узлов в кластере Hadoop.
В этом блоге описаны все полезные команды оболочки Hadoop. Наряду с командами оболочки Hadoop в нем также есть снимки экрана, упрощающие обучение. Читать дальше!
По прогнозам, большие данные и hadoop станут будущим систем управления данными. Большие данные предназначены для людей, которые переходят с мэйнфреймов на Hadoop для больших данных.
В этом посте рассказывается об операторах в Apache Pig. Взгляните на этот пост для операторов в Apache Pig: Часть 1 - Операторы отношения.
В этом посте обсуждается HBase и анализ архитектуры HBase. Здесь также обсуждаются такие компоненты Hbase, как Master, Region server и Zookeeper, а также способы их использования.
В этом сообщении описывается Apache Pig UDF - Eval, Aggregate & Filter Functions. Взгляните на функции Eval, Aggregate и Filter.
В этом посте описывается Apache Pig UDF - функции загрузки. (Apache Pig UDF: Часть 2). Взгляните на функции загрузки Apache Pig UDF.
В этом посте рассказывается о Apache Pig UDF - Store Functions. (Apache Pig UDF: Часть 3). Взгляните на функции магазина Apache Pig UDF.
В этом блоге мы узнаем об установке Apache Hive в Ubuntu и концепциях, касающихся Hadoop Hive, Hive sql, базы данных Hive, сервера Hive и установки Hive.
В этом посте описывается, как большие данные используются для расширения маркетинговых возможностей в телекоммуникационной отрасли. Читайте дальше, чтобы узнать больше о больших данных и телекоммуникационной отрасли.
Узнайте, почему инженер по тестированию программного обеспечения должен изучать большие данные и Hadoop и как обучение по работе с большими данными и сертификация Hadoop могут помочь ему получить лучшие вакансии в сфере больших данных.
В этом посте обсуждается образец Proof of Concept для HBase. Вы можете найти четкое объяснение концепции, чтобы лучше понять HBase.
Преобразование Oracle в HDFS с использованием Sqoop - ознакомьтесь с инструкциями по преобразованию Oracle в HDFS с помощью Sqoop.
Большие данные могут помочь преодолеть трудности, с которыми сталкиваются крупные организации. Ниже приведены важные примеры использования больших данных, которые используются для решения проблем, с которыми они сталкиваются.
Apache Storm популярен благодаря функциям обработки в реальном времени и был реализован именно по этой причине. Вот несколько примеров использования Apache Storm.
Существует острая потребность в администраторах Hadoop, поскольку организации быстро используют Hadoop, а любой кластер, превышающий 20–30 узлов, требует постоянного администратора.